|
|
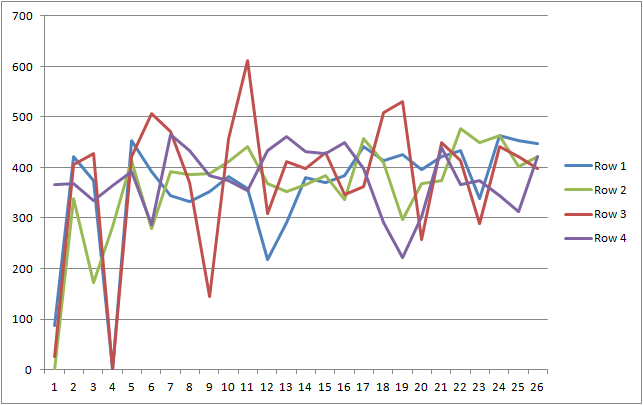
OverviewBack EMF speed control operates by monitoring the induced back EMF created by the motor windings turning within the motors static magnetic field. By regularly interrupting the PWM drive to the motor, the back EMF voltage can be measured and used to adjust the PWM drive to maintain a nominally constant speed. ImplementationThe timing for BEMF control is based upon 128 counts @ a 131us interval. The original loco decoder code takes a single ADC sample half way through this 3.7ms dead time. It has been suggested that taking several ADC samples during the sample interval and performing a median average could produce a more stable feedback term into the BEMF algorithm. Sampling AnalysisTo test the concept, I adapted my Development Board software to take ADC samples every 131 us during the sampling interval. (using the same timebase for the BEMF control) For analysis on a PC, the fresh 10 bit ADC values are immediately sent over the RS232 port and captured to a file. The captured data was then imported into Excel where charting functions can be quickly and easily performed. The following chart is of the raw ADC samples from 4 consecutive intervals. The noisy nature of these ADC samples is clearly obvious.
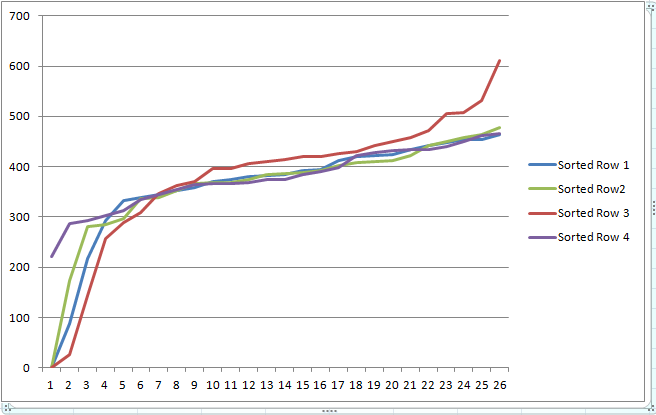
What is most interesting is the chart of these exact same samples after being sorted:
The similarity now between the previously noisy traces is absolutely stunning. One could simply take the single centre sample (#13) from the sorted data (ala median) and have a much improved estimate than would be derived from the raw time series data around sample 13 (of which sample #12 does appear to be particularly bad). Averaging several of the median ADC readings would provide an even smoother end result. 28th August 2012. |
| [Home] [Hobbies] [Model Railways] [Electronics] [Hobby Machining] [Favorites] [Photo Gallery] [Stats] |